La
unidad central de procesamiento .(del inglés
central processing unit o
CPU), es el hardware dentro de una computadora u otros dispositivos programables, que interpreta las instrucciones de un programa informático mediante la realización de las operaciones básicas aritméticas, lógicas y de entrada/salida del sistema. El término en sí mismo y su acrónimo han estado en uso en la industria de la Informática por lo menos desde el principio de los años 1960.
1 La forma, el
diseño y la implementación de las CPU ha cambiado drásticamente desde los primeros ejemplos, pero su operación fundamental sigue siendo la misma.

Una computadora puede tener más de una CPU; esto se llama multiprocesamiento. Todas las CPU modernas son microprocesadores, lo que significa que contienen un solo circuito integrado (chip). Algunos circuitos integrados pueden contener varias CPU en un solo chip; estos son denominados procesadores multinúcleo. Un circuito integrado que contiene una CPU también puede contener los dispositivos periféricos, y otros componentes de un sistema informático; a esto se llama un sistema en un chip (SoC).
Dos componentes típicos de una CPU son la unidad aritmético lógica (ALU), que realiza operaciones aritméticas y lógicas, y la unidad de control (CU), que extrae instrucciones de la memoria, las decodifica y las ejecuta, llamando a la ALU cuando sea necesario.
No todos los sistemas computacionales se basan en una unidad central de procesamiento. Una matriz de procesador o procesador vectorial tiene múltiples elementos cómputo paralelo, sin una unidad considerada el "centro". En el modelo de computación distribuido, se resuelven problemas mediante un conjunto interconectado y distribuido de procesadores.
Historia del CPU

La idea de un ordenador con programa almacenado ya estaba presente en el diseño de J. Presper Eckert
y en el ENIAC de John William Mauchly
, pero se omitió inicialmente de modo que pudiera ser terminado antes. El 30 de junio de 1945, antes de que se construyera la ENIAC, el matemático John von Neumann
distribuyó el trabajo titulado First Draft of a Report on the EDVAC (Primer Borrador de un Reporte sobre el EDVAC). Fue el esbozo de un ordenador de programa almacenado que en agosto de 1949 fue finalmente terminado.2 EDVAC fue diseñado para realizar un cierto número de instrucciones (u operaciones) de varios tipos. Significativamente, los programas escritos para el EDVAC se crearon para ser almacenados en la memoria
de alta velocidad del ordenador y no especificado por el cableado físico del ordenador. Esto superó una severa limitación del ENIAC, que era el importante tiempo y esfuerzo requerido para volver a configurar el equipo para realizar una nueva tarea. Con el diseño de von Neumann, el programa o software, que corría EDVAC podría ser cambiado simplemente cambiando el contenido de la memoria. Sin embargo, EDVAC no fue el primer ordenador de programa almacenado; la Máquina Experimental de Pequeña Escala de Mánchester
, un pequeño prototipo de ordenador de programa almacenado, corrió su primer programa el 21 de junio de 19483 y la Manchester Mark I
corrió su primer programa en la noche del 16 hasta el 17 junio de 1949.Ordenadores, como el ENIAC tenían que ser físicamente recableados para realizar diferentes tareas, que causaron que estas máquinas se llamarán "ordenadores de programas fijo". Dado que el término "CPU" generalmente se define como un dispositivo para la ejecución de software (programa informático), los primeros dispositivos que con razón podríamos llamar CPU vinieron con el advenimiento del ordenador con programa almacenado.
Las primeras CPU fueron diseñadas a medida como parte de un ordenador más grande, generalmente un ordenador único en su especie. Sin embargo, este método de diseñar las CPU a medida, para una aplicación particular, ha desaparecido en gran parte y se ha sustituido por el desarrollo de clases de procesadores baratos y estandarizados adaptados para uno o varios propósitos. Esta tendencia de estandarización comenzó generalmente en la era de los transistores discretos, computadoras centrales y microcomputadoras y fue acelerada rápidamente con la popularización del circuito integrado (IC), éste ha permitido que sean diseñados y fabricados CPU más complejas en espacios pequeños en la orden de nanómetros). Tanto la miniaturización como la estandarización de las CPU han aumentado la presencia de estos dispositivos digitales en la vida moderna mucho más allá de las aplicaciones limitadas de máquinas de computación dedicadas. Los microprocesadores modernos aparecen en todo, desde automóviles hasta teléfonos móviles o celulares y juguetes de niños.
Si bien von Neumann muchas veces acreditado por el diseño de la computadora con programa almacenado debido a su diseño del EDVAC, otros antes que él, como Konrad Zuse, habían sugerido y aplicado ideas similares. La denominada arquitectura Harvard del Harvard Mark I, que se completó antes de EDVAC, también utilizó un diseño de programa almacenado usando cinta de papel perforada en vez de memoria electrónica. La diferencia clave entre las arquitecturas de von Neumann y la de Harvard es que la última separa el almacenamiento y tratamiento de instrucciones de la CPU y los datos, mientras que el primero utiliza el mismo espacio de memoria para ambos. La mayoría de los CPU modernos son de diseño von Neumann, pero los CPU con arquitectura Harvard se ven así, sobre todo en aplicaciones embebidas; por ejemplo, los microcontroladores Atmel AVR son procesadores de arquitectura Harvard.
Los relés eléctricos y los tubos de vacío (válvulas termoiónicas) eran usados comúnmente como elementos de conmutación; un ordenador útil requiere miles o decenas de miles de dispositivos de conmutación. La velocidad global de un sistema depende de la velocidad de los conmutadores. Los ordenadores de tubo, como el EDVAC, tendieron en tener un promedio de ocho horas entre fallos, mientras que los ordenadores de relés, (anteriores y más lentos), como el Harvard Mark I, fallaban muy raramente.
1 Al final, los CPU basados en tubo llegaron a ser dominantes porque las significativas ventajas de velocidad producidas generalmente pesaban más que los problemas de confiabilidad. La mayor parte de estas tempranas CPU síncronas corrían en frecuencias de reloj bajas comparadas con los modernos diseños microelectrónicos. Eran muy comunes en este tiempo las frecuencias de la señal del reloj con un rango desde 100 kHz hasta 4 MHz, limitado en gran parte por la velocidad de los dispositivos de conmutación con los que fueron construidos.
Microprocesadores
Las generaciones previas de CPU fueron implementadas como componentes discretos y numerosos circuitos integrados de pequeña escala de integración en una o más tarjetas de circuitos. Por otro lado, los microprocesadores son CPU fabricados con un número muy pequeño de IC; usualmente solo uno. El tamaño más pequeño del CPU, como resultado de estar implementado en una simple pastilla, significa tiempos de conmutación más rápidos debido a factores físicos como el decrecimiento de la capacitancia
parásita de las puertas
. Esto ha permitido que los microprocesadores síncronos tengan tiempos de reloj con un rango de decenas de megahercios a varios gigahercios. Adicionalmente, como ha aumentado la capacidad de construir transistores excesivamente pequeños en un IC, la complejidad y el número de transistores en un simple CPU también se ha incrementado dramáticamente. Esta tendencia ampliamente observada es descrita por la ley de Moore
, que ha demostrado hasta la fecha, ser una predicción bastante exacta del crecimiento de la complejidad de los CPUs y otros IC.6En la década de 1970 los inventos fundamentales de Federico Faggin (ICs Silicon Gate MOS con puertas autoalineadas junto con su nueva metodología de diseño de lógica aleatoria) cambió el diseño e implementación de las CPU para siempre. Desde la introducción del primer microprocesador comercialmente disponible, el Intel 4004, en 1970 y del primer microprocesador ampliamente usado, el Intel 8080, en 1974, esta clase de CPU ha desplazado casi totalmente el resto de los métodos de implementación de la Unidad Central de procesamiento. Los fabricantes de mainframes y miniordenadores de ese tiempo lanzaron programas de desarrollo de IC propietarios para actualizar sus arquitecturas de computadorasmás viejas y eventualmente producir microprocesadores con conjuntos de instrucciones que eran retrocompatibles con sus hardwares y softwares más viejos. Combinado con el advenimiento y el eventual vasto éxito de la ahora ubicua computadora personal, el término "CPU" es aplicado ahora casi exclusivamente a los microprocesadores.
Mientras que, en los pasados sesenta años han cambiado drásticamente, la complejidad, el tamaño, la construcción y la forma general de la CPU, es notable que el diseño y el funcionamiento básico no ha cambiado demasiado. Casi todos los CPU comunes de hoy se pueden describir con precisión como máquinas de programa almacenado de von Neumann.A medida que la ya mencionada ley del Moore continúa manteniéndose verdadera, se han presentado preocupaciones sobre los límites de la tecnología de transistor del circuito integrado. La miniaturización extrema de puertas electrónicas está causando los efectos de fenómenos que se vuelven mucho más significativos, como la electromigración y el subumbral de pérdida. Estas nuevas preocupaciones están entre los muchos factores que hacen a investigadores estudiar nuevos métodos de computación como la computación cuántica, así como ampliar el uso de paralelismo y otros métodos que extienden la utilidad del modelo clásico de von Neumann.
Diseño e implementación
Rango de enteros

La manera en que un CPU representa los números es una opción de diseño que afecta las más básicas formas en que el dispositivo funciona. Algunas de las primeras calculadoras digitales usaron, para representar números internamente, un modelo eléctrico del sistema de numeración decimal común (base diez). Algunas otras computadoras han usado sistemas de numeración más exóticos como el ternario (base tres). Casi todos los CPU modernos representan los números en forma binaria, en donde cada dígito es representado por una cierta cantidad física de dos valores, como un voltaje "alto" o "bajo".
El rango del número entero también puede afectar el número de posiciones en memoria que el CPU puede direccionar (localizar). Por ejemplo, si un CPU binario utiliza 32 bits para representar una dirección de memoria, y cada dirección de memoria representa a un octeto
(8 bits), la cantidad máxima de memoria que el CPU puede direccionar es 232 octetos, o 4GB. Ésta es una vista muy simple del espacio de dirección
del CPU, y muchos diseños modernos usan métodos de dirección mucho más complejos como paginación
para localizar más memoria que su rango entero permitiría con un espacio de dirección plano.Con la representación numérica están relacionados el tamaño y la precisión de los números que un CPU puede representar. En el caso de un CPU binario, un
bit se refiere a una posición significativa en los números con que trabaja un CPU. El número de bits (o de posiciones numéricas, o dígitos) que un CPU usa para representar los números, a menudo se llama "tamaño de la palabra", "ancho de bits", "ancho de ruta de datos", o "precisión del número entero" cuando se ocupa estrictamente de números enteros (en oposición a números de coma flotante). Este número difiere entre las arquitecturas, y a menudo dentro de diferentes unidades del mismo CPU. Por ejemplo, un CPU de 8 bits maneja un rango de números que pueden ser representados por ocho dígitos binarios, cada dígito teniendo dos valores posibles, y en combinación los 8 bits teniendo 2
8 ó 256 números discretos. En efecto, el tamaño del número entero fija un límite de hardware en el rango de números enteros que el software corre y que el CPU puede usar directamente.
Niveles más altos del rango de números enteros requieren más estructuras para manejar los dígitos adicionales, y por lo tanto, más complejidad, tamaño, uso de energía, y generalmente costo. Por ello, no es del todo infrecuente, ver microcontroladores de 4 y 8 bits usados en aplicaciones modernas, aun cuando están disponibles CPU con un rango mucho más alto (de 16, 32, 64, e incluso 128 bits). Los microcontroladores más simples son generalmente más baratos, usan menos energía, y por lo tanto disipan menos calor. Todo esto pueden ser consideraciones de diseño importantes para los dispositivos electrónicos. Sin embargo, en aplicaciones del extremo alto, los beneficios producidos por el rango adicional, (más a menudo el espacio de dirección adicional), son más significativos y con frecuencia afectan las opciones del diseño. Para ganar algunas de las ventajas proporcionadas por las longitudes de bits tanto más bajas, como más altas, muchas CPUs están diseñadas con anchos de bit diferentes para diferentes unidades del dispositivo. Por ejemplo, el IBM System/370 usó un CPU que fue sobre todo de 32 bits, pero usó precisión de 128 bits dentro de sus unidades de coma flotante para facilitar mayor exactitud y rango de números de coma flotante. Muchos diseños posteriores de CPU usan una mezcla de ancho de bits similar, especialmente cuando el procesador está diseñado para usos de propósito general donde se requiere un razonable equilibrio entre la capacidad de números enteros y de coma flotante.
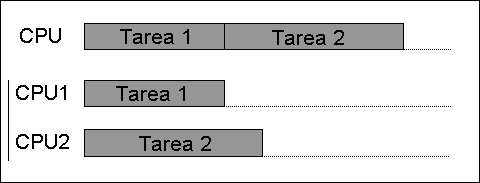
Paralelismo
Este proceso da lugar a una ineficacia inherente en CPU subescalares. Puesto que solamente una instrucción es ejecutada a la vez, todo el CPU debe esperar que esa instrucción se complete antes de proceder a la siguiente instrucción. Como resultado, la CPU subescalar queda "paralizado" en instrucciones que toman más de un ciclo de reloj para completar su ejecución. Incluso la adición de una segunda unidad de ejecución (ver abajo) no mejora mucho el desempeño. En lugar de un camino quedando congelado, ahora dos caminos se paralizan y aumenta el número de transistores no usados. Este diseño, en donde los recursos de ejecución de la CPU pueden operar con solamente una instrucción a la vez, solo puede, posiblemente, alcanzar el desempeño escalar (una instrucción por ciclo de reloj). Sin embargo, el desempeño casi siempre es subescalar (menos de una instrucción por ciclo).La descripción de la operación básica de un CPU ofrecida en la sección anterior describe la forma más simple que puede tomar un CPU. Este tipo de CPU, usualmente referido como subescalar, opera sobre y ejecuta una sola instrucción con una o dos piezas de datos a la vez.

Las tentativas de alcanzar un desempeño escalar y mejor, han resultado en una variedad de metodologías de diseño que hacen comportarse al CPU menos linealmente y más en paralelo. Cuando se refiere al paralelismo en los CPU, generalmente son usados dos términos para clasificar estas técnicas de diseño.
- El paralelismo a nivel de instrucción, en inglés instruction level parallelism (ILP), busca aumentar la tasa en la cual las instrucciones son ejecutadas dentro de un CPU, es decir, aumentar la utilización de los recursos de ejecución en la pastilla.
- El paralelismo a nivel de hilo de ejecución, en inglés thread level parallelism (TLP), que se propone incrementar el número de hilos (efectivamente programas individuales) que un CPU pueda ejecutar simultáneamente.
Cada metodología se diferencia tanto en las maneras en las que están implementadas, como en la efectividad relativa que producen en el aumento del desempeño de la CPU para una aplicación.

 es la fracción de tiempo que un programa gasta en partes no paralelizables, luego Idealmente, la aceleración a partir de la paralelización es lineal, doblar el número de elementos de procesamiento debe reducir a la mitad el tiempo de ejecución y doblarlo por segunda vez debe nuevamente reducir el tiempo a la mitad. Sin embargo, muy pocos algoritmos paralelos logran una aceleración óptima. La mayoría tienen una aceleración casi lineal para un pequeño número de elementos de procesamiento, y pasa a ser constante para un gran número de elementos de procesamiento.
es la fracción de tiempo que un programa gasta en partes no paralelizables, luego Idealmente, la aceleración a partir de la paralelización es lineal, doblar el número de elementos de procesamiento debe reducir a la mitad el tiempo de ejecución y doblarlo por segunda vez debe nuevamente reducir el tiempo a la mitad. Sin embargo, muy pocos algoritmos paralelos logran una aceleración óptima. La mayoría tienen una aceleración casi lineal para un pequeño número de elementos de procesamiento, y pasa a ser constante para un gran número de elementos de procesamiento.
 procesadores es
procesadores es